Bạn đang tìm hiểu Logging là gì và vai trò của nó trong hệ thống phần mềm? Bài viết này từ Fast Byte sẽ đi sâu vào định nghĩa, tầm quan trọng, các cấp độ Logging phổ biến, đồng thời hướng dẫn cách thiết kế một hệ thống Logging hiệu quả và các công cụ hỗ trợ tốt nhất hiện nay.
Logging là gì?
Logging, hay ghi log, là hành động ghi lại một cách có hệ thống các sự kiện, thông điệp, hoặc dữ liệu phát sinh trong quá trình hoạt động của một ứng dụng, phần mềm, hoặc hệ thống máy tính. Mỗi bản ghi (log record) được tạo ra giống như một dòng nhật ký, chứa thông tin về một sự kiện cụ thể đã xảy ra tại một thời điểm nhất định.
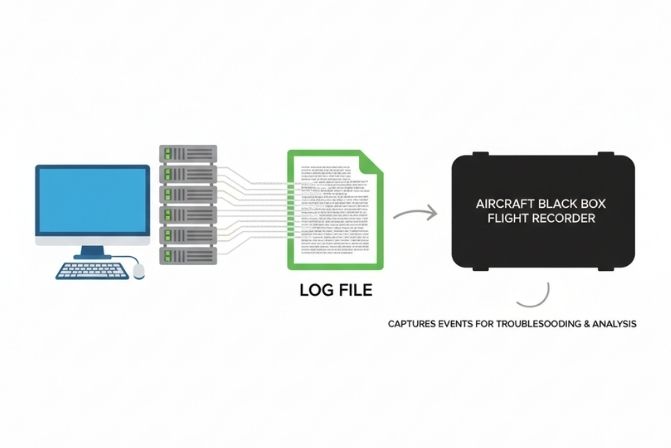
Hãy hình dung Logging giống như hộp đen của một chiếc máy bay. Khi chuyến bay diễn ra suôn sẻ, không ai cần đến nó. Nhưng khi sự cố xảy ra, hộp đen là công cụ vô giá giúp các chuyên gia hiểu chính xác những gì đã diễn ra, nguyên nhân gốc rễ của vấn đề. Tương tự, trong phát triển phần mềm, các file log chính là “hộp đen” chứa đựng toàn bộ lịch sử hoạt động, giúp lập trình viên truy vết và sửa lỗi hiệu quả.
Sản phẩm cuối cùng của quá trình Logging là các bản ghi log, thường được lưu trữ trong các tệp văn bản gọi là log file, hoặc được gửi đến các hệ thống quản lý log chuyên dụng.
Tầm quan trọng của Logging trong hệ thống phần mềm
Việc ghi log không chỉ là một thói quen tốt mà còn là một yêu cầu thiết yếu trong việc phát triển và vận hành phần mềm chuyên nghiệp. Tầm quan trọng của Logging thể hiện rõ rệt qua những lợi ích cốt lõi sau:
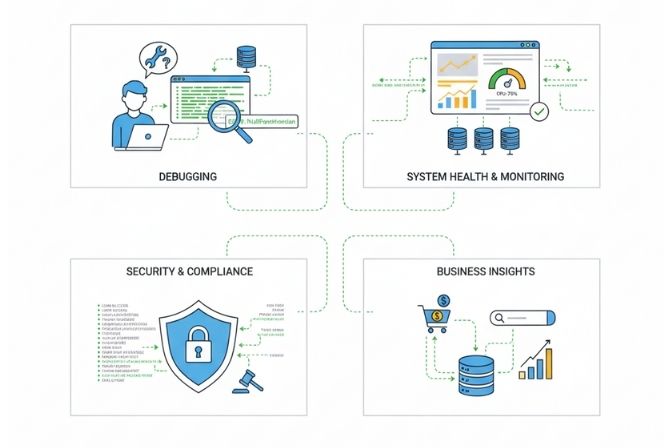
Gỡ lỗi và khắc phục sự cố (Debugging & Troubleshooting)
Đây là vai trò cơ bản và quan trọng nhất của Logging. Khi một lỗi xảy ra trên môi trường sản phẩm (production), lập trình viên không thể chạy trình gỡ lỗi (debugger) trực tiếp.
Lúc này, log là nguồn thông tin duy nhất giúp họ tái hiện lại luồng xử lý, xác định chính xác vị trí và nguyên nhân gây ra lỗi. Một thông điệp log tốt sẽ cung cấp đủ ngữ cảnh về những gì đã xảy ra ngay trước khi lỗi xuất hiện.
Giám sát sức khỏe hệ thống (System Monitoring)
Thông qua việc phân tích log theo thời gian thực, đội ngũ vận hành (DevOps, SRE) có thể theo dõi “mạch đập” của hệ thống. Các chỉ số như tần suất lỗi tăng đột biến, thời gian phản hồi một yêu cầu kéo dài bất thường, hay việc sử dụng tài nguyên (CPU, bộ nhớ) quá mức đều có thể được phát hiện sớm qua log. Điều này cho phép họ can thiệp kịp thời trước khi sự cố nhỏ leo thang thành vấn đề lớn ảnh hưởng đến người dùng.
Phân tích bảo mật (Security Analysis)
Hệ thống Logging là tuyến phòng thủ quan trọng trong việc đảm bảo an ninh. Log ghi lại mọi hành vi truy cập, từ các lần đăng nhập thành công, đăng nhập thất bại, cho đến các yêu cầu truy cập tài nguyên bị từ chối.
Bằng cách phân tích các log bảo mật, quản trị viên có thể phát hiện các dấu hiệu của một cuộc tấn công mạng, chẳng hạn như tấn công dò mật khẩu (brute-force) hay cố gắng khai thác lỗ hổng.
Phân tích hành vi người dùng và hỗ trợ quyết định kinh doanh
Logging không chỉ dành cho mục đích kỹ thuật. Bằng cách ghi lại các hành động quan trọng của người dùng (ví dụ: người dùng A đã thêm sản phẩm B vào giỏ hàng, người dùng C đã sử dụng tính năng tìm kiếm với từ khóa D), các nhà phân tích dữ liệu có thể hiểu rõ hơn về cách người dùng tương tác với sản phẩm. Dữ liệu này là đầu vào quý giá để cải thiện trải nghiệm người dùng, tối ưu hóa các luồng chức năng và đưa ra các quyết định kinh doanh chiến lược.
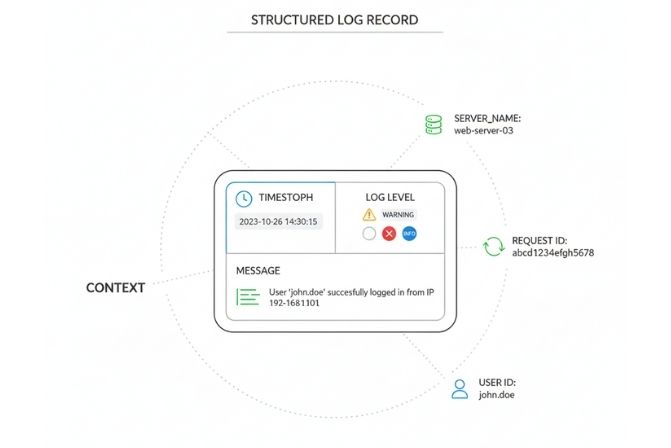
Các thành phần cốt lõi của một bản ghi Log
Để một bản ghi log thực sự hữu ích, nó cần chứa đựng những thông tin cơ bản và đầy đủ ngữ cảnh. Một cấu trúc log tiêu chuẩn thường bao gồm các thành phần sau:
Timestamp (Dấu thời gian)
Đây là thành phần bắt buộc, ghi lại thời điểm chính xác (ngày, giờ, phút, giây, mili giây) mà sự kiện xảy ra. Dấu thời gian giúp sắp xếp các sự kiện theo đúng trình tự và là yếu tố quan trọng nhất khi phân tích một chuỗi sự cố.
Log Level (Cấp độ Log)
Cấp độ log cho biết mức độ nghiêm trọng hoặc tầm quan trọng của thông điệp log. Việc phân loại này giúp lập trình viên có thể nhanh chóng lọc ra các thông tin quan trọng (như lỗi) giữa hàng ngàn thông điệp thông tin khác.
Message (Nội dung)
Đây là phần mô tả chính về sự kiện đã diễn ra. Nội dung log cần được viết một cách rõ ràng, súc tích và cung cấp thông tin có giá trị. Ví dụ: “Không thể kết nối đến cơ sở dữ liệu tại địa chỉ XYZ” tốt hơn nhiều so với một thông điệp chung chung như “Có lỗi xảy ra”.
Context (Ngữ cảnh)
Thông tin ngữ cảnh là yếu tố làm cho một bản ghi log trở nên thực sự mạnh mẽ. Đây là các dữ liệu bổ sung giúp làm rõ hoàn cảnh xảy ra sự kiện. Ví dụ về thông tin ngữ cảnh bao gồm:
- Tên máy chủ hoặc container đang chạy ứng dụng.
- ID của yêu cầu (Request ID) để nhóm tất cả log liên quan đến một yêu cầu duy nhất.
- ID của người dùng đang thực hiện hành động.
- Tên của lớp (class) và phương thức (method) đang thực thi.
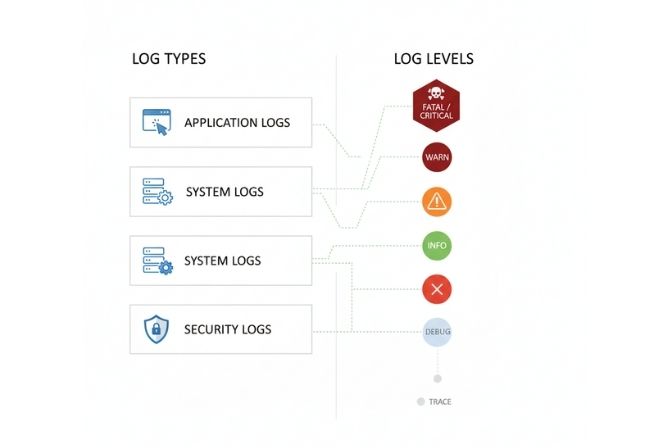
Các loại Log và phân cấp mức độ Log phổ biến
Không phải tất cả các log đều giống nhau. Chúng có thể được phân loại dựa trên nguồn gốc và mức độ quan trọng để việc quản lý và phân tích trở nên dễ dàng hơn.
Phân loại Log
Application Logs (Log ứng dụng)
Đây là loại log phổ biến nhất, được chính ứng dụng của bạn tạo ra trong quá trình hoạt động. Chúng ghi lại mọi thứ từ luồng nghiệp vụ, hành vi người dùng, cho đến các lỗi phát sinh bên trong mã nguồn. Lập trình viên có toàn quyền kiểm soát nội dung và định dạng của loại log này.
System Logs (Log hệ thống)
Loại log này được tạo ra bởi hệ điều hành hoặc các dịch vụ nền tảng mà ứng dụng đang chạy trên đó. Ví dụ như log về việc khởi động dịch vụ, sử dụng tài nguyên hệ thống (CPU, RAM), hoặc các lỗi ở cấp độ phần cứng. Trên Linux, chúng thường được quản lý bởi syslog hoặc journald.
Security Logs (Log bảo mật)
Đây là một tập con đặc biệt của log, chuyên ghi lại các sự kiện liên quan đến an ninh. Ví dụ bao gồm các lần đăng nhập thành công và thất bại, các nỗ lực truy cập vào tài nguyên bị cấm, hoặc các thay đổi về quyền hạn người dùng.
Phân cấp mức độ Log (Log Levels)
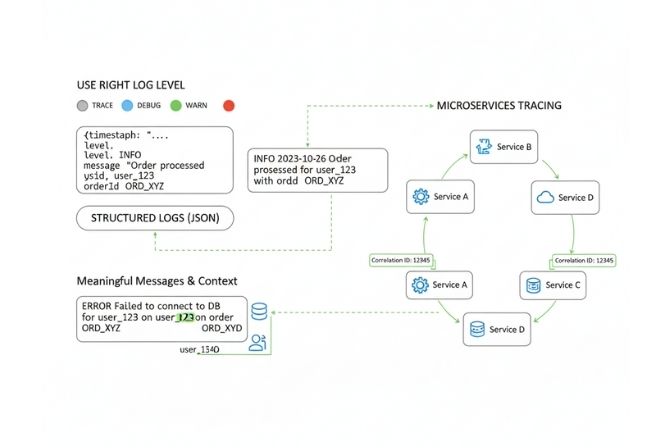
Việc phân cấp mức độ cho phép chúng ta kiểm soát độ chi tiết của log. Trên môi trường phát triển, bạn có thể muốn thấy mọi thứ (DEBUG). Nhưng trên môi trường sản phẩm, bạn chỉ muốn ghi lại những thông tin thực sự quan trọng (INFO, WARN, ERROR) để tránh làm quá tải hệ thống và tốn chi phí lưu trữ.
TRACE / VERBOSE
Mức độ chi tiết nhất, thường ghi lại các bước đi cực nhỏ trong một thuật toán hoặc luồng xử lý. Mức độ này rất ít khi được sử dụng, trừ khi cần gỡ lỗi một vấn đề vô cùng phức tạp.
DEBUG
Cung cấp thông tin chi tiết hữu ích cho việc gỡ lỗi trong môi trường phát triển. Ví dụ: giá trị của các biến, đầu vào và đầu ra của một hàm. Mức độ này nên được tắt trên môi trường production.
INFORMATION (INFO)
Ghi lại các sự kiện quan trọng, đánh dấu các cột mốc trong luồng hoạt động bình thường của ứng dụng. Ví dụ: “Ứng dụng đã khởi động thành công”, “Người dùng XYZ đã đăng nhập”, “Một đơn hàng mới đã được tạo”. Đây là mức độ mặc định trên hầu hết các hệ thống production.
WARNING (WARN)
Ghi lại những tình huống bất thường hoặc không mong muốn đã xảy ra, nhưng ứng dụng vẫn có thể tiếp tục hoạt động. Ví dụ: “API của bên thứ ba phản hồi chậm”, “Cấu hình X không được tìm thấy, sử dụng giá trị mặc định”. Đây là những dấu hiệu cần được chú ý.
ERROR
Ghi lại các lỗi đã xảy ra và làm ảnh hưởng đến một chức năng cụ thể, nhưng không làm toàn bộ ứng dụng bị sập. Ví dụ: “Không thể xử lý thanh toán cho đơn hàng 123 do thẻ không hợp lệ”, “Không thể gửi email xác nhận cho người dùng”. Các log ERROR cần được theo dõi và xử lý ngay lập tức.
FATAL / CRITICAL
Đây là mức độ nghiêm trọng nhất, ghi lại những lỗi thảm khốc khiến toàn bộ ứng dụng hoặc một thành phần cốt lõi phải dừng hoạt động. Ví dụ: “Không thể kết nối đến cơ sở dữ liệu chính, ứng dụng sẽ dừng lại”. Một log FATAL thường đòi hỏi sự can thiệp ngay lập tức của con người.
Thực hành tốt khi triển khai Logging (Best Practices)
Để hệ thống Logging thực sự phát huy hiệu quả, việc tuân thủ các nguyên tắc và thực hành tốt là vô cùng cần thiết.
Sử dụng Structured Logging (ghi log có cấu trúc)
Thay vì ghi log dưới dạng một chuỗi văn bản thuần túy, hãy sử dụng định dạng có cấu trúc như JSON.
Log văn bản (không tốt): [2025-10-27 10:30:00] ERROR: Payment failed for user 123 and order 456.
Log có cấu trúc (tốt):
{
"timestamp": "2025-10-27T10:30:00Z",
"level": "ERROR",
"message": "Payment failed",
"userId": 123,
"orderId": 456
}Log có cấu trúc giúp máy tính dễ dàng đọc, phân tích, tìm kiếm và lọc dữ liệu. Bạn có thể dễ dàng truy vấn “tìm tất cả các lỗi của người dùng 123” mà không cần phải phân tích chuỗi văn bản phức tạp.
Sử dụng đúng Log Level cho từng trường hợp
Phân loại log một cách chính xác. Đừng ghi một lỗi nghiêm trọng ở mức INFO, và cũng đừng ghi một thông tin hoạt động bình thường ở mức ERROR. Việc sử dụng sai cấp độ sẽ làm nhiễu loạn hệ thống giám sát và khiến bạn bỏ lỡ các vấn đề quan trọng.
Nội dung log phải có ý nghĩa và cung cấp đủ ngữ cảnh
Một thông điệp log như “Lỗi” hoặc “Xảy ra ngoại lệ” là hoàn toàn vô dụng. Hãy đảm bảo rằng thông điệp log mô tả rõ ràng điều gì đã xảy ra, và quan trọng hơn, cung cấp các dữ liệu ngữ cảnh liên quan (ví dụ: ID đơn hàng, ID người dùng, tham số đầu vào) để giúp việc tái hiện lỗi trở nên dễ dàng.
Tích hợp ID tương quan (Correlation ID)
Trong các hệ thống hiện đại, đặc biệt là kiến trúc microservices, một yêu cầu của người dùng có thể đi qua nhiều dịch vụ khác nhau. Một Correlation ID là một mã định danh duy nhất được tạo ra ở dịch vụ đầu tiên và truyền đi qua tất cả các dịch vụ tiếp theo.
Bằng cách ghi lại ID này trong mọi bản ghi log, bạn có thể dễ dàng xâu chuỗi và truy vết toàn bộ hành trình của một yêu cầu qua toàn bộ hệ thống.
Lưu ý và tránh các lỗi phổ biến khi ghi Log
Triển khai Logging sai cách có thể gây ra nhiều vấn đề hơn là giải quyết chúng. Dưới đây là những sai lầm phổ biến cần tránh:
Không ghi log các thông tin nhạy cảm
Đây là lỗi nghiêm trọng nhất. Tuyệt đối không bao giờ ghi lại các thông tin như mật khẩu, số thẻ tín dụng, API key, hoặc bất kỳ dữ liệu cá nhân nhạy cảm nào của người dùng vào log. Việc rò rỉ log file có thể dẫn đến những hậu quả khôn lường về bảo mật và pháp lý (tuân thủ GDPR, CCPA).
Tránh ghi log quá nhiều (verbose logging) trên môi trường production
Việc bật log ở mức DEBUG hoặc TRACE trên môi trường sản phẩm sẽ tạo ra một lượng dữ liệu khổng lồ. Điều này không chỉ gây tốn kém chi phí lưu trữ và xử lý mà còn có thể làm giảm hiệu năng của ứng dụng do phải thực hiện quá nhiều thao tác ghi đĩa (I/O).
Tránh các thông điệp log vô nghĩa, chung chung
Như đã đề cập, các thông điệp như “Đã xong”, “Lỗi rồi”, “Vào hàm X” không mang lại giá trị gì. Hãy luôn tự hỏi: “Nếu tôi chỉ đọc dòng log này, tôi có hiểu được chuyện gì đang xảy ra không?”.
Không “nuốt” exception mà không ghi log lại
Một lỗi phổ biến của các lập trình viên ít kinh nghiệm là sử dụng một khối try-catch trống để bắt lỗi và bỏ qua nó.
// KHÔNG NÊN LÀM
try {
// Một đoạn mã có thể gây lỗi
} catch (Exception e) {
// Bỏ qua lỗi, không làm gì cả
}Hành động này làm cho lỗi “biến mất” một cách âm thầm, khiến việc gỡ lỗi gần như không thể. Ít nhất, bạn phải ghi lại thông tin về exception đó trong khối catch.

Thiết kế hệ thống Logging hiệu quả trong dự án thực tế
Xây dựng một chiến lược Logging không chỉ là việc thêm vài dòng lệnh ghi log vào mã nguồn. Nó đòi hỏi một cách tiếp cận có hệ thống.
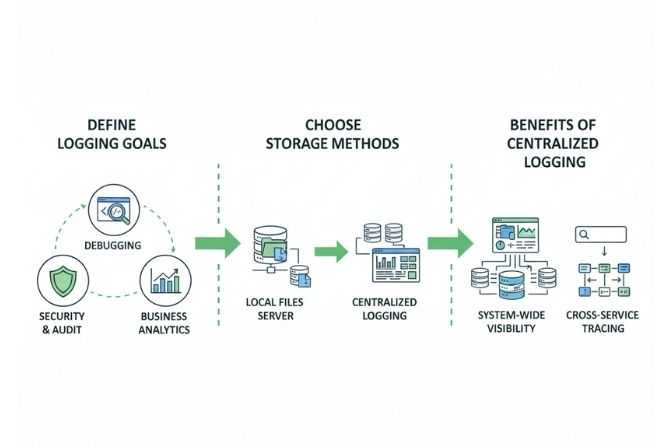
Xác định mục tiêu Logging
Trước khi viết bất kỳ dòng log nào, hãy trả lời các câu hỏi:
- Chúng ta cần ghi log để làm gì? Để gỡ lỗi, để kiểm toán (audit), để phân tích kinh doanh, hay tất cả?
- Ai sẽ là người đọc log này? Lập trình viên, đội ngũ DevOps, hay chuyên viên phân tích dữ liệu?
- Thông tin nào là quan trọng nhất cần phải ghi lại cho mỗi chức năng?
Lựa chọn phương pháp ghi Log và nơi lưu trữ dữ liệu Log
Có nhiều cách để lưu trữ log:
- Ghi ra file cục bộ: Đơn giản nhất, phù hợp cho các ứng dụng đơn lẻ. Tuy nhiên, việc quản lý và truy cập log sẽ khó khăn khi có nhiều máy chủ.
- Gửi tới Syslog Server: Một cách tiếp cận truyền thống để tập trung hóa log trong một mạng nội bộ.
- Đẩy vào một hệ thống log tập trung: Đây là phương pháp hiện đại và hiệu quả nhất, sẽ được nói rõ ở phần sau.
Centralized Logging (Ghi log tập trung)
Trong các hệ thống phân tán và microservices, việc để log nằm rải rác trên hàng chục, hàng trăm máy chủ là một cơn ác mộng. Logging tập trung là giải pháp thu thập log từ tất cả các nguồn (ứng dụng, máy chủ, dịch vụ) và gom chúng về một nơi duy nhất. Điều này mang lại lợi ích to lớn:
- Tìm kiếm và phân tích dễ dàng: Bạn có thể truy vấn toàn bộ log của hệ thống từ một giao diện duy nhất.
- Cái nhìn toàn cảnh: Dễ dàng tương quan các sự kiện xảy ra trên các dịch vụ khác nhau.
- Quản lý tập trung: Dễ dàng quản lý việc lưu trữ, vòng đời và quyền truy cập vào log.
Công cụ và công nghệ hỗ trợ Logging hiện nay
Hệ sinh thái Logging rất phong phú với nhiều thư viện và nền tảng mạnh mẽ.
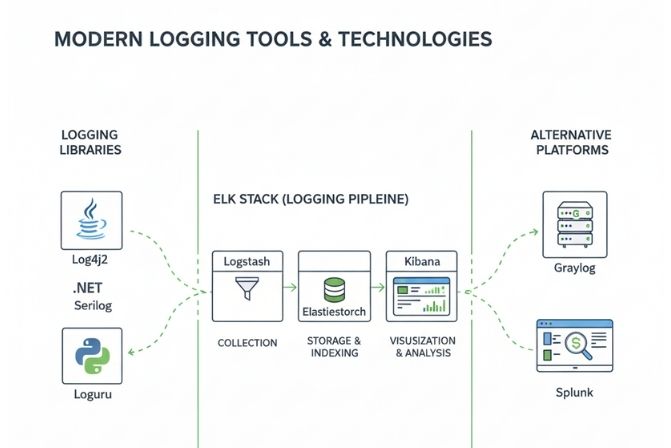
Thư viện Logging theo ngôn ngữ
Mỗi ngôn ngữ lập trình đều có các thư viện phổ biến giúp việc ghi log trở nên đơn giản và mạnh mẽ.
- Java: Log4j2, SLF4J & Logback là những lựa chọn hàng đầu.
- .NET: Serilog nổi bật với khả năng hỗ trợ structured logging tuyệt vời, bên cạnh NLog và Log4net.
- Python: Thư viện
loggingcó sẵn là một khởi đầu tốt, Loguru là một lựa chọn hiện đại và dễ sử dụng hơn.
Hệ thống quản lý và phân tích Log
Đây là các nền tảng dùng để triển khai Logging tập trung.
- ELK Stack (Elasticsearch, Logstash, Kibana): Là bộ ba công cụ mã nguồn mở cực kỳ phổ biến. Logstash thu thập và xử lý log, Elasticsearch lưu trữ và lập chỉ mục, còn Kibana cung cấp giao diện web để trực quan hóa và tìm kiếm log.
- Graylog: Một giải pháp mã nguồn mở khác, được xem là một đối thủ cạnh tranh mạnh mẽ của ELK Stack, thường được đánh giá là dễ cài đặt và quản lý hơn.
- Splunk: Một giải pháp thương mại rất mạnh mẽ, cung cấp nhiều tính năng phân tích nâng cao nhưng đi kèm với chi phí bản quyền.
Phân tích và giám sát Log để nâng cao hiệu năng hệ thống
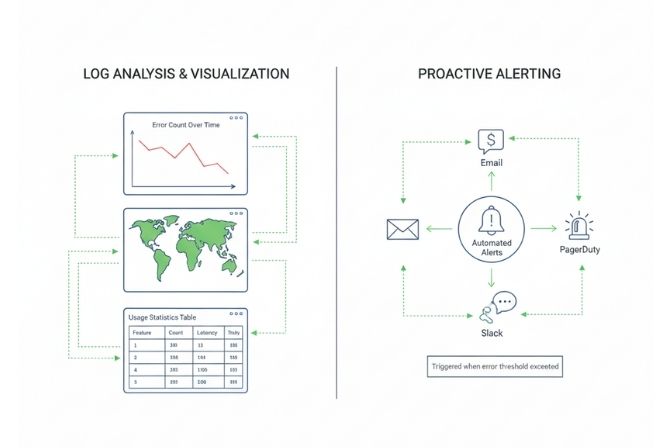
Thu thập log chỉ là bước đầu tiên. Giá trị thực sự nằm ở việc phân tích và hành động dựa trên dữ liệu đó.
Sử dụng các công cụ như Kibana hoặc Grafana, bạn có thể tạo ra các dashboard để trực quan hóa các chỉ số quan trọng từ log, ví dụ như biểu đồ số lượng lỗi mỗi giờ, bản đồ các khu vực có nhiều người dùng truy cập nhất, hoặc bảng thống kê các tính năng được sử dụng nhiều nhất.
Một tính năng quan trọng khác là thiết lập cảnh báo (alerting). Hệ thống có thể tự động gửi thông báo (qua email, Slack, PagerDuty) cho đội ngũ vận hành khi phát hiện các dấu hiệu bất thường, chẳng hạn như số lượng log ERROR vượt qua một ngưỡng nhất định trong 5 phút. Điều này giúp phát hiện và phản ứng với sự cố một cách chủ động.
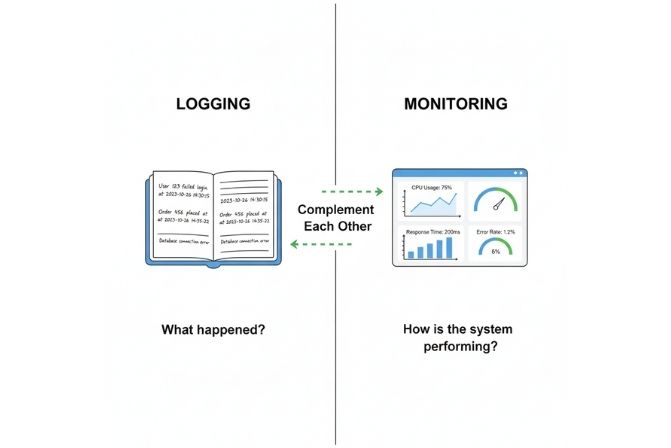
Phân biệt Logging và Monitoring
Nhiều người thường nhầm lẫn giữa Logging và Monitoring (Giám sát), nhưng chúng là hai khái niệm bổ trợ cho nhau.
| Tiêu chí | Logging | Monitoring |
|---|---|---|
| Mục đích | Ghi lại các sự kiện rời rạc, không thể đoán trước. Trả lời câu hỏi: “Cái gì đã xảy ra?” | Theo dõi các chỉ số (metrics) được xác định trước theo thời gian. Trả lời câu hỏi: “Hệ thống đang hoạt động như thế nào?” |
| Dữ liệu | Dữ liệu dạng văn bản, có hoặc không có cấu trúc (events). | Dữ liệu dạng số (numbers, time-series). |
| Ví dụ | “User 123 failed to log in”, “Order 456 was placed”. | “CPU usage is 80%”, “Average response time is 200ms”, “500 errors per minute”. |
| Bản chất | Phản ứng (ghi lại những gì đã xảy ra trong quá khứ). | Chủ động (quan sát những gì đang xảy ra ở hiện tại). |
Một hệ thống quan sát (observability) toàn diện cần cả Logging, Monitoring và Tracing (truy vết).
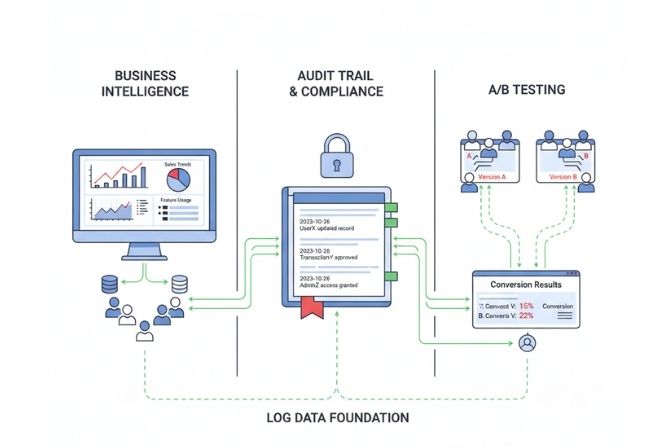
Ứng dụng của Logging trong phát triển và vận hành
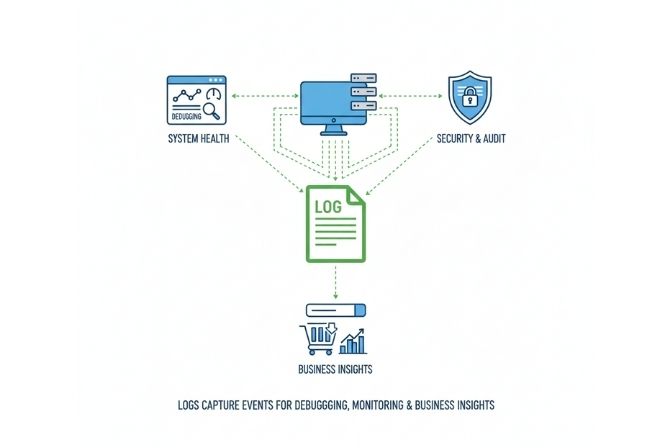
Ngoài mục đích chính là gỡ lỗi, dữ liệu từ Logging còn có nhiều ứng dụng giá trị khác.
Business Intelligence (Phân tích kinh doanh)
Dữ liệu log về hành vi người dùng là một mỏ vàng. Bằng cách phân tích các log này, doanh nghiệp có thể hiểu được sản phẩm nào bán chạy nhất, tính năng nào được yêu thích, hoặc khách hàng thường bỏ cuộc ở bước nào trong quy trình thanh toán.
Audit Trail (Dấu vết kiểm toán)
Trong các hệ thống yêu cầu tính tuân thủ cao (tài chính, y tế), Logging được sử dụng để tạo ra một dấu vết kiểm toán không thể thay đổi. Mọi hành động quan trọng như “ai đã thay đổi dữ liệu khách hàng X”, “ai đã phê duyệt giao dịch Y” đều phải được ghi lại chi tiết.
A/B Testing
Khi triển khai một tính năng mới theo dạng A/B testing (phiên bản A cho nhóm người dùng này, phiên bản B cho nhóm khác), Logging là công cụ để ghi lại tương tác và tỷ lệ chuyển đổi của mỗi nhóm. Dữ liệu này giúp xác định phiên bản nào hoạt động hiệu quả hơn.
Câu hỏi thường gặp về Logging (FAQ)
Ghi log quá nhiều có ảnh hưởng đến hiệu năng không?
Có. Việc ghi log, đặc biệt là ghi ra đĩa, là một thao tác I/O có thể gây tốn tài nguyên và làm chậm ứng dụng nếu được thực hiện quá thường xuyên. Đây là lý do tại sao cần sử dụng các cấp độ log một cách hợp lý và tắt các log chi tiết (DEBUG, TRACE) trên môi trường production.
Khi nào nên sử dụng Log Level DEBUG?
Chỉ nên sử dụng mức DEBUG trong quá trình phát triển và gỡ lỗi trên máy cục bộ hoặc trên môi trường test. Nó cung cấp thông tin chi tiết về luồng thực thi và giá trị biến, giúp lập trình viên hiểu sâu hơn về mã nguồn của mình.
Structured Logging có thực sự cần thiết không?
Rất cần thiết, đặc biệt trong các hệ thống phức tạp. Mặc dù việc thiết lập ban đầu có thể tốn công hơn một chút, nhưng lợi ích về khả năng tìm kiếm, phân tích và tự động hóa mà nó mang lại trong dài hạn là vô cùng lớn. Nó là nền tảng cho một hệ thống Logging hiện đại và hiệu quả.
Lời kết
Qua bài viết, Fast Byte hy vọng bạn đã có một cái nhìn toàn diện về Logging là gì và tại sao nó lại là một kỹ năng không thể thiếu của bất kỳ lập trình viên chuyên nghiệp nào. Logging không chỉ đơn thuần là việc ghi lại thông tin, mà là một nghệ thuật giúp xây dựng nên những phần mềm ổn định, dễ bảo trì và có khả năng quan sát cao.
Việc đầu tư thời gian để thiết kế một chiến lược Logging bài bản ngay từ đầu sẽ mang lại những lợi ích to lớn trong suốt vòng đời của dự án.